-
2-1 데이터 입출력 구현자격증/정처기 2023. 5. 16. 05:44
1.자료구조
-어떠한 자료구조에서도 필요한 모든 연산들을 처리하는 것이 가능하다
1)배열
- 동일한 자료형, 크기의 데이터를 순서대로 나열
- 정적 = 데이터 추가가 어렵고 데이터 삭제시 빈공간으로 남아 메모리 낭비
- 반복에 유리, 동일한 변수 이름
- arr[2]에서 arr은 변수 이름, 2는 첨자(subscript)
2)선형리스트
- 연속 리스트(배열): 배열의 삽입과 삭제 개선 (밀도 1)
- 연결 리스트(포인터): 삽입과 삭제에 용이, 포인터 = 공간 효율이나 속도가 구림
*노드 = data + link(포인터)
3)스택
- 후입선출 (LIFO)
- 재귀호출, DFS, 전/후위표기, 퀵정렬
- 함수 호출 제어, 복귀주소, 인터럽트, 수식 계산, 컴파일러 언어 번역
- Push땐 TOP을 1 증가시키고 Overflow 체크,
- Pop땐 Underflow 체크후 TOP을 1 감소
4)큐
- 선입선출 (FIFO)
- 운영체제 스케쥴링에 사용
- F = Front, R = Rear
*Rear은 다음 삽입 위치가 아닌 마지막 자료 위치
+데큐(deque): 양방향 = 스택으로도, 큐로도 쓸 수 있음
5)그래프
- 그래프 G, 정점 V = Vertex, 간선 E = Edge
- 방향, 무방향 그래프로 나뉨
- 정점이 N개면 최대 간선수는 N(N-1), N(N-1)/2
- 통신망 + 이항관계, 연립방정식, 화학구조식, 무향선분
*트리: 싸이클이 없는 크래프
*그래프와 트리는 비선형구조
2.트리
- 정점(Node)와 선분 = 가지(Branch) = 링크 = 서브트리로 구성
- Root = "근"
- 잎(Leaf) = 단말(Terminal) 노드
- 차수(degree) - 아래로 연결된 노드 수
*트리의 차수는 degree중 최대값
트리 운행(Traversal)

C랑 H 제외 1)Preorder: Root - Left - Right // ABE-FJK-DGLI *루트가 무조건 시작
2)Inorder: Left - Root - Right // E-B-JFK-A-LGDI
3)Postorder: Left - Right - Root // E-JKF-B-LGIDA *루트가 무조건 마지막
수식 표기
1)전위(prefix) +AB
2)중위(infix) A+B
3)후위(postfix) AB+
*전/후위는 스택으로 처리 가능, 중위는 둘중 하나로 변경
3.정렬
1)삽입 정렬
- N번째 키를 이전 N-1개의 키와 전부 비교
- N번째 키를 맞는 위치로 옮기고 나머지를 뒤로 한칸씩 옮김
85624
85624 -> [58]624
58624 -> [568]24
56824 -> [2568]4
25684 -> [24568]
2)쉘 정렬
- 삽입 정렬의 개선판
- 매개변수 H칸 떨어져 있는 키의 값을 비교
- 평균 O(N^1.5), 최악 O(N^2)
3)선택 정렬
- N번째 키를 이후 (M-N)개의 값중 최소값과 교환
85624
[85624] -> [25684]
2[5684] -> 2[4685]
24[685] -> 24[586]
245[86] -> 24568
4)버블 정렬
- 서로 인접한 값을 비교
- 플래그 비트를 통해 정렬이 완료 됐는지 체크해야함
85624 -> [58]624 -> 5[68]24 -> 56[28]4 -> 562[48] -> 5[26]48 -> 52[46]8 -> [25]468 -> 2[45]68
5)퀵정렬
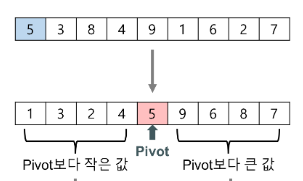
- 기준값 피봇을 중심으로 분할, 정복
- 가장 빠름, 스택 필요
6)힙 정렬
-전이진 트리 = 완전 이진 트리 = Complete Binary Tree를 힙 트리로 변환
*힙: 부모의 값이 자식보다 항상 큼/작음
*루트가 최대값이면 max heap, 최소값이면 min heap
7)2-WAY 합병 정렬 (Merge Sort)
85624913
[85] [62] [49] [13]
[58] [26] [49] [13]
[2568] [1349]
[12345689]
*퀵은 분할이, 머지는 합병이 중심
8)기수 정렬 (Radix = Bucket sort)
-큐를 이용하여 자릿수별로 정렬
시간 복잡도
삽입, 선택, 버블 // 평균, 최악 O(n^2)
힙, 머지 // 평균 최악 O(nlog2n)
퀵 평균O(nlog2n), 최악 O(n^2)
4.검색
1)이분 검색
1~100에서 50 찾기
(1+100)/2 = 50.5 = 50 -> 15는 50보다 작으므로 1~49 탐색
*정렬되어있어야 함
2)해싱
- 버킷: 하나의 주소를 갖는 파일의 한 구역
*버킷 크기 = 같은 주소에 포함 가능한 레코드(슬롯) 수
- Synonym: 충돌(Collision)로 인해 같은 주소를 갖는 레코드의 집합
해싱 함수
1.제산법: 키(K)를 소수(Q)로 나눈 나머지를 주소값으로 사용
*Q는 테이블 크기보다 큰 소수중 가장 작은 값
2.제곱법: 키 값을 제곱 후 중간 값 사용 (256 -> 256*256 = 262144 -> 26[21]44 -> 21 사용)
3.폴딩법: 키 값을 여러 부분으로 나눠 더하거나 XOR
4.기수 변환: 진수 변환 (10진수 64를 16진수 6*16+4*1 = 100으로 변경)
5.대수적 코딩법:키 값을 계수로 한 다항식 -> 해시 다항식으로 나눠 얻은 값 사용
6.숫자 분석법: 키 값의 분포를 고려, 분포가 고른 자리값을 골라 사용
7.무작위법: 랜덤
+ 개방 주소법(순차), 폐쇄 주소법(포인터)
5.DBMS
-통합, 저장, 운영, 공용 데이터
-필수 기능: 정의(D), 조작(M), 제어(C)
정의: 모든 자료형 정의
조작: 검색, 삽입, 삭제 등 기능(인터페이스 수단) 제공
제어: 정확한 수행(무결성,안정성), 보안(권한), 병행 제어(동시 접근)
DDL(정의) - 스키마나 테이블을 정의 / 변경 / 삭제 할때 사용
DML(조작) - SELECT(검색), INSERT, UPDATE, DELETE
DCL(제어) - 보안, 회복, 병행제어
스키마
- DB의 구조와 제약조건에 관한 명세(Specification) 집합
- 데이터 개체(엔티티), 속성, 관계, 제약 조건에 대해 정의
- 사용자 관점에 따라 구분됨
1)외부 스키마 - 개인의 필요에 따른 정의
2)개념 스키마 - 전체적인 논리 관점, 하나만 존재
3)내부 스키마 - 물리적 저장장치 관점
트랜잭션
- 논리적 수행의 단위
- TCL: COMMIT or ROLLBACK (-> SAVEPOINT)
절차형 SQL
- 효율은 떨어지지만 연속적인 제어 가능
- 프로시저(일련의 작업 수행, 함수와 비슷), 트리거 (이벤트마다 관련 작업 수행), 사용자 정의 함수 (리턴값 무조건 있음)
데이터 접속
- SQL 맵핑: SQL문을 직접 입력해 DB에 접속 -> JDBC, ODBC, Mybatis
- ORM: (객체 지향 프로그래밍의) 객체와 (관계형) DB의 데이터를 연결 -> JPA, Hibernate, Django
'자격증 > 정처기' 카테고리의 다른 글
2-3 어플리케이션 테스트 관리 (0) 2023.05.17 2-2 소프트웨어 패키징 (0) 2023.05.16 1-4 인터페이스 설계 (0) 2023.05.14 1-3 어플리케이션 설계 (0) 2023.05.14 1-2 화면 설계 (0) 2023.05.14