-
이미지 크롤링으로 블로그 포스팅 자동화토이 프로젝트 2023. 1. 18. 16:43
https://blog.naver.com/PostList.naver?blogId=khs20010327
코교's 코딩 & 유머 블로그 : 네이버 블로그
당신의 모든 기록을 담는 공간
blog.naver.com

블로그를 핀터레스트와 연계하며 조회수 대박이 났다.
하지마 매일매일 자료를 수집하고 글을 쓰는것도 지치기에
이를 자동화해보기로 결심했다.
https://github.com/Paperplane5555/naver-blog-original-image-crawler
GitHub - Paperplane5555/naver-blog-original-image-crawler: 네이버 블로그 원본 이미지 크롤러
네이버 블로그 원본 이미지 크롤러. Contribute to Paperplane5555/naver-blog-original-image-crawler development by creating an account on GitHub.
github.com
참조한 코드

os 모듈 - 운영체제가 제공하는 기능을 파이썬에서 수행
-> setting.txt 파일에 적혀있는 경로에 크롤링한 사진을 모음


이후 다운로드, 카테고리 다운로드, 저장 경로 변경 기능을 제공하며

다운로드는 input으로 입력받은 url을 인자로 download() 함수를 호출한다

download 함수에선 입력받은 url을 모바일 url로 변경하는데,



pc 블로그 코드 네이버 블로그의 경우 pc 환경에선 <body> 파트를 iframe으로 처리하고 있어서 크롤링이 불가능하고

모바일 블로그 코드 모바일 환경에선 사진 등 source를 전부 지니고있기에 모바일 url로 크롤링을 진행한다
https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=eye_korea&logNo=220834780778
모바일에서 iframe
모바일 웹 브라우저에서 iframe 사용은 자제해야 한다. 그렇지 않으면 굉장히 피곤해 진다. iframe 은 현재...
blog.naver.com
모바일 환경에서 iframe을 사용하지 않는 이유는 위와같은 이유 때문인듯하다.

이후 requests 모듈로 url의 html 내용을 받아오고,
beautifulsoup로 soup 객체를 생성한다
이제 우리가 크롤링해야할 것은 글의 제목과 사진인데, 일단 제목부터.


제목은 "og:title"이란 프로터피값을 지닌 <meta>의 content에 존재하므로,
이를 soup 객체에 find 메서드를 통해 뽑아낸다


그 다음에 얻은 title 값을 바탕으로 디렉토리를 생성한다.
clean_text()는 제목에 특수문자를 제거하여 오류를 방지하는 함수이다.

글의 제목을 디렉토리 이름으로 해두면 나중에 글을 쓸때도 편해진다

그 다음은 이미지 크롤링.


사진의 경우 photo_view_property란 id값을 지닌 <div>의 AttachImagePathAndIDInfo 안에 순서대로 저장되어있다.
이 역시 soup.find를 통해 가져오고,

filebox의 [attach] 값을
strip(), replace(), split() 메서드로 정리하면 이미지 하나당
dummy값 + 소스 링크 + dummy 값 3개로 이루어진 배열이 생성된다

이제 반복문을 통해 위에서 얻은 소스 링크를 얻고,
*pstatic.net은 네이버의 이미지 데이터 관련 서버 주소

크롤링할 게시글이 하나면 앞서 선언한 전역변수 onlyone 값이 True이므로 바로 끝나고,
여러개일 경우 onlyone은 False, 총 몇개(linklist)의 글중 몇번째(repeated)글이 다운로드중인지 출력한다
urllib.request.urlretrieve(link, save_path+clean_text(urllib.parse.unquote(link.split('/')[-1])))다운로드는 다음 코드로 수행되는데,
urlib.request.urlretrieve(url, savename)은
url에 존재하는 파일을 savename으로 저장,
url은 위에서 얻은 link 변수이며,


위 link를 '/'를 기준으로 split하면 맨 뒤 = [-1]가 사진의 파일명이고
quote()는 웹 서버나 브라우저가 인식하기 좋은 ascii값으로 치환,
urlib.parse.unquote()는 이를 반대로 역치환하여 사람이 읽을 수 있는 값으로 수정한다
그 다음엔 cleantext()로 오류방지,
그리고 위에서 구한 savepath에 저장한다

카테고리에 존재하는 여러 글을 한번에 크롤링할 경우엔
category_download() 함수가 호출되며,


작은 카테고리 다운엔 linkget(), 큰 카테고리 다운엔 linkget_allcategory() 함수를 호출한다
이는 인자로 받은 url과 같은 카테고리인 게시글의 url 목록을 리턴해준느 함수이다.

linkget() 함수는 일단 download()와 마찬가지로 모바일 url로 변경하고 soup 객체를 생성한다

그 다음 html에서 category 번호와 블로그 id를 꺼내오고,
(raise는 강제로 오류를 일으키는 기능)


다음과 같은 url을 생성한다
postTtitleListAsync는 해당 블로그(blogId) 카테고리(category)의 게시글들에 대한 정보를 지니고있으며
각 글의 url 은 logNo에 저장되어있다.
마찬가지로 requests로 내용을 읽어온 뒤 문자열로 바꿔준다


tagQueryString 뒤에 url들이 순서대로 모여져있으니 앞부분을 split으로 제거해주고


logNO를 기준으로 다시 split, 큰따음표를 remove()로 제거해주면
필요한 url 뒷부분 값으로만 구성된 배열이 완성된다

그리고 위를 보면 알듯이 같은 값이 반복되는데,
이는 카테고리 내 게시글 목록을 전부 출력하면 마지막엔 같은 값을 반복해서 출력하기 때문이다.
그렇기에 중복되는 값이 존재하는지 체크하여 여러분 중복이 발생하면 반복문을 break해준다
쨋든 이렇게 만들어진 url 목록을 return하고,

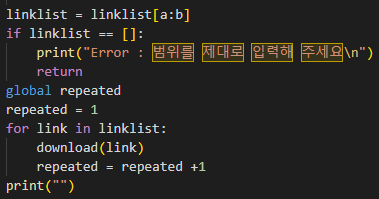
다시 category_download() 함수로 돌아와
다운로드할 범위를 input으로 입력받은 뒤
해당 값들을 인자로 download() 함수를 호출한다

그 다음은 큰 카테고리의 게시글 전체를 다운로드하는 3번 기능.
마찬가지로 category_download()를 호출하며,
category_download()는 linkget()대신 linkget_allcategory() 함수를 호출한다
input으로 게시글이 아닌 다음과 같은 카테고리 url을 입력받으며,

split으로 분리하여 blogId, categoryNo 값을 얻는다
이후 해당 값으로 url 목록을 return 하는것은 linkget() 함수와 동일하니 생략


실행 결과 정상적으로 크롤링 된다
에러 체크도 다 되어있고
게시글, 작은 카테고리, 큰 카테고리 다운 기능을 전부 제공하는 등
내가 원하는 기능을 대부분 갖춘 정말 좋은 프로그램이지만..

내가 크롤링하려는 유머 카테고리는 글이 수만개인 경우가 많다
위 코드의 경우 전체 목록을 얻은 뒤 원하는 부분만 지정하여 크롤링 하는데,
100개의 글을 크롤링하기위해 수만개의 글 목록을 전부 체크하는 것은 비효율적이다
물론 내가 좀 많이 특수한 경우지만...
그러므로 범위를 먼저 지정한 뒤 그 부분을 크롤링 하도록
새롭게 프로그램을 작성해보기로 했다
import requests from bs4 import BeautifulSoup import urllib.request import urllib.parse import os import re def clean_text(inputString): text_rmv = re.sub('[\\\/:*?"<>|]', ' ', inputString) text_rmv = text_rmv.strip() return text_rmv id = 'khs20010327' category = '592' start = 2 number = 100 end = int(number/5 + start) dir = "C:/Users/user/Desktop/Naverblog" os.chdir(dir) linklist=[] for i in range (start, end): category_url = "https://blog.naver.com/PostTitleListAsync.naver?blogId="+id+"&viewdate=¤tPage="+str(i)+"&parentCategoryNo="+category+"&countPerPage=5" categoryresponse = requests.get(category_url) categorytext = categoryresponse.text categorysoup = categorytext.split('"tagQueryString":"')[1].replace('"}', '') logNo = categorysoup.split("&logNo=") logNo.remove("") for i2 in logNo: link = "https://m.blog.naver.com/"+id+"/"+i2 response = requests.get(link) soup = BeautifulSoup(response.content, 'html.parser') title = soup.find('meta', property="og:title")['content'] file_box = soup.find('div', id='_photo_view_property') file = file_box['attachimagepathandidinfo'].strip("[""]").replace('"path"', '').replace('"id"', '').split('"') save_path = "./"+clean_text(title)+"/" if not os.path.exists("./"+clean_text(title)): os.makedirs("./"+clean_text(title)) for i in range(0, 9999): k = i*2 + 1 try: filelink = "https://blogfiles.pstatic.net" +file[k] except: print("완료\n") break urllib.request.urlretrieve(filelink, save_path+clean_text(urllib.parse.unquote(filelink.split('/')[-1])))전체 코드
id = 'khs20010327' category = '592' start = 2 number = 100 end = int(number/5 + start)블로그의 id와 category, 기존 코드는 url에서 해당 값을 얻어냈지만
그냥 url의 아이디와 카테고리 번호를 입력하는게 더 편할 것 같아서 변수로 넣었다.
start는 시작지점, number는 크롤링 할 게시글 개수.
end는 두 값을 기준으로 계산해낸다
for i in range (start, end): category_url = "https://blog.naver.com/PostTitleListAsync.naver?blogId="+id+"&viewdate=¤tPage="+str(i)+"&parentCategoryNo="+category+"&countPerPage=5" categoryresponse = requests.get(category_url) categorytext = categoryresponse.text categorysoup = categorytext.split('"tagQueryString":"')[1].replace('"}', '') logNo = categorysoup.split("&logNo=") logNo.remove("")id와 category 값으로 url 목록을 얻는 파트
for i2 in logNo: link = "https://m.blog.naver.com/"+id+"/"+i2 response = requests.get(link) soup = BeautifulSoup(response.content, 'html.parser') title = soup.find('meta', property="og:title")['content'] file_box = soup.find('div', id='_photo_view_property') file = file_box['attachimagepathandidinfo'].strip("[""]").replace('"path"', '').replace('"id"', '').split('"') save_path = "./"+clean_text(title)+"/" if not os.path.exists("./"+clean_text(title)): os.makedirs("./"+clean_text(title))url 목록을 바탕으로 soup 객체를 만들어
title과 file 데이터를 얻는 파트
for i in range(0, 9999): k = i*2 + 1 try: filelink = "https://blogfiles.pstatic.net" +file[k] except: print("완료\n") break urllib.request.urlretrieve(filelink, save_path+clean_text(urllib.parse.unquote(filelink.split('/')[-1])))마지막으로 파일을 다운로드하는 파트
기존 코드와 달리
저장 경로를 변경하거나
잘못된 값을 입력하여 예외 처리를 진행하는 파트가 없다보니
코드가 훨씬 간결해졌다.

프로그램도 정상적으로 수행!
https://www.youtube.com/watch?v=iDQM4SLOep4
이후 업로드는 시중에 존재하는 매크로 프로그램을 활용
이제 매일매일 자동으로 블로그 글이 올라간다.
이렇게 편한줄 알았으면 진작 할껄
'토이 프로젝트' 카테고리의 다른 글
OpenCV를 활용한 화면 감지 프로그램 (1) 2023.12.10 익성비 기대값 계산기 만들기 (0) 2023.06.30 섯다 계산기 만들기 (0) 2023.01.07 스크래치로 테트리스 만들기 (0) 2022.07.08 메이플 몬스터 시메지 (+ 모바일) (0) 2022.07.06