-
연산 순서

From -> Where
Group by -> Having
Select -> Order by
DISTINCT
- Select distinct A, B from table
-> {a,b} 둘 다 같아야 제거됨
Alias
- Select col1 as A from table
- as 생략 가능
- 별칭은 where절에서 사용 불가
ex) select A+B as SUM from table where SUM > 1000 에러발생
Limit

* RANK() = 1,1,3,4 DENSE_RANK = 1,1,2,3 ROW_NUMBER = 1,2,3,4
Order by
- 느림
- order by a2, a1 desc -> a2 오름차순 이후 a1 내림차순
- order by 2,1 desc
- 컬럼명, 별칭, 숫자 전부 혼용 가능
- 실행 순서는 select 이후 order by 이지만 전체 행을 메모리에 올리기에 select에 없는 속성으로 정렬이 가능하다.
Group by
- null도 하나의 그룹
- select엔 그룹화에 쓴 컬럼과 집계함수만 올 수 있음
ex) SELECT class, count(*) FROM student GROUP BY class
- group by 없이 having 사용 가능 (테이블 전체가 1개의 그룹인 경우)
ex) SELECT sum(cnt) FROM student HAVING max(cnt)>100
그룹함수
https://for-my-wealthy-life.tistory.com/44
SQL 집계함수 - ROLLUP, CUBE, GROUPING SETS
SQL의 집계함수에 대해 살펴보겠습니다. 보통 GROUP BY절 외에 ROLLUP, CUBE 등 다양한 그룹함수에 대해서도 같이 알아보겠습니다. 1. GROUP BY 절 SELECT 상품ID, 월, SUM(매출액) AS 매출액 FROM 월별매출 GROUP B
for-my-wealthy-life.tistory.com
ROLLUP - 계층적 = 인수 순서 중요
GroupingSets - 인수 순서 상관 x (계층 구조 평등)
CUBE - 모든 경우의 수 = 부하 큼 // 인수 순서 상관 X
groupingSets(A,B) = group by A + group by B
rollup(A,B) = group by (A,B) +group by (A) *인자 순서 중요!
cube(A,B) = group by A + B + AB + (테이블 그룹) = grouping sets (a, b, (a,b), ())
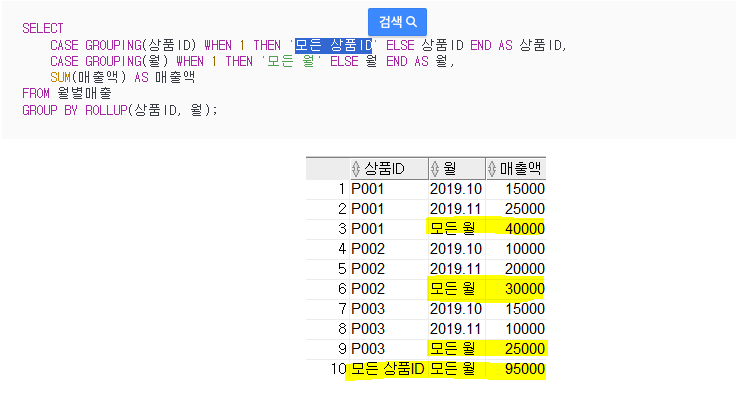
GROUPING - 집게 결과 선택에 사용
=========================================================================
Natural join
- 동일한 이름 + 호환되는 타입을 가진 컬림이 필요
- 컬럼을 명시하지 않아도 자동으로 조인
- 컬럼 앞에 테이블 명 안붙임
- select * from A natural join B
Using
- select * from A join B using (id)
Left join
- 왼쪽에 있는건 전부 출력, 겹치는게 있으면 오른쪽도 붙여서 출력
- select * from A left outer join B on A.id = B.id
- 오라클: select * from A,B where A.id = B.id(+)
- and B.col(+) = 'n' and A.col = 'y' => SQL문으로 치환시 B의 조건은 on절로, A의 조건은 where절에 작성된다.

- full outer join = left UNION right
* CROSS JOIN에 ON 조건절로 INNER JOIN처럼 쓸 수는 있다. 굳이 의미는 없다.
집합
- Union all : 정렬 X, 중복 제거 X = 빠름
- Union, Intersect(교집합), Minus(차집합) = 느림
- Union, Intersect, minus를 하면 기존에 존재하던 중복도 전부 제거된다
- 정렬(order by)는 무조건 집합 이후 실행
해시 조인
- 무조건 등가 join만 사용 (a = b)
- 선행 테이블이 작으면 유리
- 해시 처리를 위한 별도의 메모리 공간 필요
- 해시를 사용한다 = 정렬 사용 안함 = 대용량 작업에 유리
- join 컬럼의 인덱스가 없어도 사용 가능
NestLoop
- 랜덤 액세스

Sort Merge Join
- 조인되는 N개의 테이블을 모두 정렬한 후 조인 수행
- join 컬럼의 인덱스가 없어도 사용 가능
*NL = OLTP // 머지 & 해시 = DW
Like join
a = { smith, allen, scott }
b = { s%, %t%}
a.name LIKE b.rule 조인시
s% = smith, scott = 2
%t% = smith, scott = 2
count(*) = 4 가 된다
A left join B ~~ where A in (1,2) -> 조인 후 A가 1이나 2인 것만 남김
A left join B on A in(1,2) -> A가 1이나 2인 것만 조인함 = A가 1이나 2가 아닌것도 출력은 됨
=========================================================================
NULL
- 모르는 값, 정의되지 않은 값
- 공백이나 0과는 다름
- NULL 사칙연산은 무조건 NULL
- NULL 비교연산은 무조건 False (null= null // null+2 < null+4 // null in (null,1,2))
- null, 1 in (null, 1) -> 1만 뽑힘
- a, b not in (null) -> 무조건 아무것도 안뽑힘
- 집계 함수에선 제외됨 AVG(1,2,3,NULL) = 2
- SUM에 NULL 있으면 알아서 빠짐!!
- COUNT(A)에선 NULL이 제외되지만 COUNT(*)에선 세진다
- 정렬시 오라클에선 가장 큰 값, SQL에선 가장 작은 값 취급 *min max는 정렬이 아닌 집계
-> ORDER BY col DESC NULLS LAST / FIRST
- group by로 나눌때 null도 하나의 그룹.
- IsNULL(A,B) A가 null이면 B, 아니면 A 반환
- NVL(A,B) A가 null이면 B, 아니면 A 반환
- NVL2(A,B,C) A가 null이면 C, 아니면 B 반환
- NULLIF(A,B) A==B면 NULL, 아니면 A 반환
- COALESCE(A,B,C...) Null이 아닌 첫번째 값 반환

Math
- Round(222.45, 1) -> 소수 첫째 자리까지 출력 = 둘째 자리에서 반올림
- Trunc (222.45, 1) -> 소수 첫째 자리까지 출력 = 둘째 자리에서 버림
* -1이면 일의 자리에서 반올림 = 0이 1개
- 올림 = ceil (오라클) // ceiling (SQL)
- 내림 = floor
String
- lpad('A',5,'K') = KKKKA
- Substr('korea',2,3) = 2번째 글자 포함 3개 = ore
- Insrt('aaabbb', 'ab') = 3
Concat
- SQL : a+b+c
- Oracle : a || b || c
- concat(a,b) *인자 2개?
조건문
- Decode( col1, 'a', 1, 'b', 2, 3)
- case when col1 = 'a' then 1
when col1 = 'b' then 2 *col2로 바꿀 수 있음
else 3 end;
- case col1 when 'a' then 1
when 'b' then 2
else 3 end;
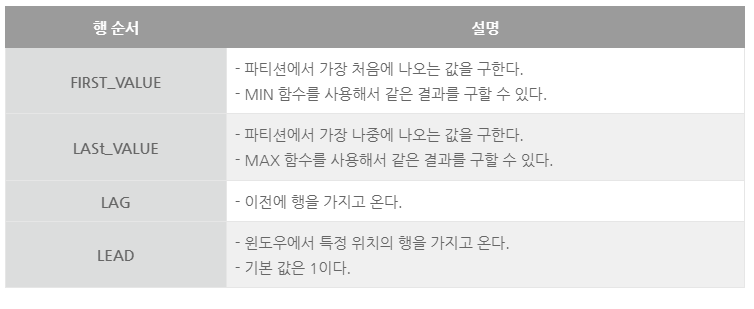
윈도우 함수
[SQL][SQLD][SQLP] 윈도우 함수
윈도우 함수 SELECT WINDOW_FUNCTION([컬럼]) OVER ( [PARTITION BY 컬럼] [ORDER BY 컬럼] [WINDOWING 절] ) FROM 테이블명 ; 윈도우 함수는 로우 간의 관계를 구할 수 있도록 만들어 놓은 함수이다. 로우 간의 순위, 집
camel-context.tistory.com
- Select 사원명, 매출액, Rank() over ( order by 매출액 DESC) as 순위 from 사원 order by 순위
- Select 부서명, 매출액, Rank() over ( partition by 부서번호 order by 매출액 DESC) as 순위 from 사원 order by 순위
- Select 부서명, 매출액, Sum() over ( order by 부서번호 ROWS UNBOUNDED PRECEDING) as 매출액합계 from 사원
- Select 부서명, 매출액, Sum() over ( order by 부서번호 ROWS 1 PRECEDING) as 매출액합계 from 사원
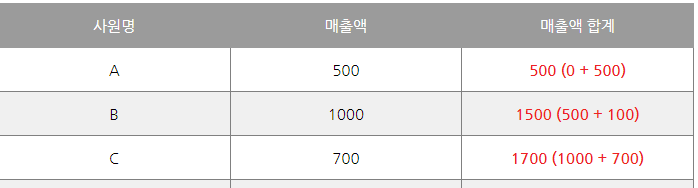
ROWS between UNBOUNDED PRECEDING and current row -> 누적 합계
ROWS between 1 preceding and 1 following -> 위아래 합계
* partition by로 나뉘면 해당 파티션의 가장 위/아래를 따진다
* RANK() = 1,1,3,4 DENSE_RANK = 1,1,2,3 ROW_NUMBER = 1,2,3,4
SELECT DEPT_ID, SALARY FROM ( SELECT ROW_NUMBER() OVER(PARTITION BY DEPT_ID ORDER BY SALARY DESC) RN, DEPT_ID, SALARY FROM SQLD_34_27 ) WHERE RN = 1;SELECT DEPT_ID, MAX(SALARY) AS SALARY FROM SQLD_34_27 GROUP BY DEPT_ID부서명으로 파티션해 연봉 내림차순으로 정렬 후 순위 매김 = 부서 명으로 GROUP BY해 MAX값
* 일반적으로 group by 와 위도우 함수 병행 불가,
-> group by로 묶은 다음 그에대한 sum이나 avg 값에 윈도우 함수는 사용 가능
* 집계 윈도우 함수(sum,max,min)을 윈동
SUM(amount) OVER (ORDER BY sale_date) AS running_total* 집계 윈도우 함수(sum,max,min)을 window 절과 함꼐 사용시 레코드 범위 지정 가능
* 윈도우 함수를 사용해도 결과 건수는 절대로 줄지 않는다
절차적 SQL
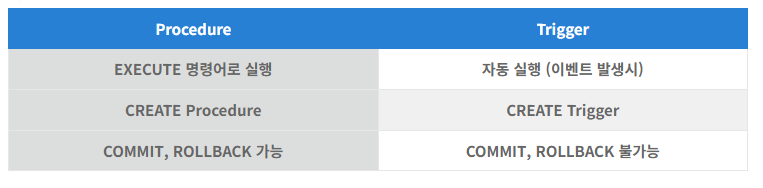
* 트리거는 커밋, 롤백 불가 (중요)
* 둘다 CREATE로 생성하지만 프로시저만 EXECUTE로 실행.
계층 SQL
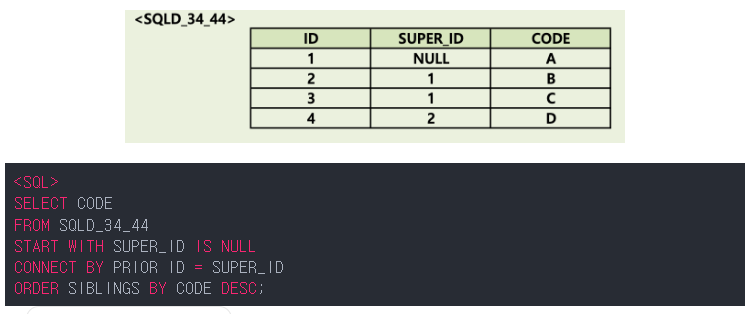

Start With -> 시작점. 루트 = 레벨 1
conenct by -> 조건문. 1의 자식 2,3 -> 2의 자식 4
order siblings -> 같은 레벨끼리 정렬. A의 자식 B와 C중 3이 크므로 3이 앞에 온다
만약 A의 자식으로 B와 C가 있고 C의 자식으로 D가 있었다면 A C D B 순으로 정렬된다. (자식이 같이 이동)
이후 where절의 조건에 해당 안되는게 나오면 바로 stop
*no cycle = 중복이 생기면 루프 stop
=========================================================================
SQL
DML = select insert update delete + MERGE
DDL = create alter drop + RENAME
DCL = grant revoke
TCL = COMMIT ROLLBACK
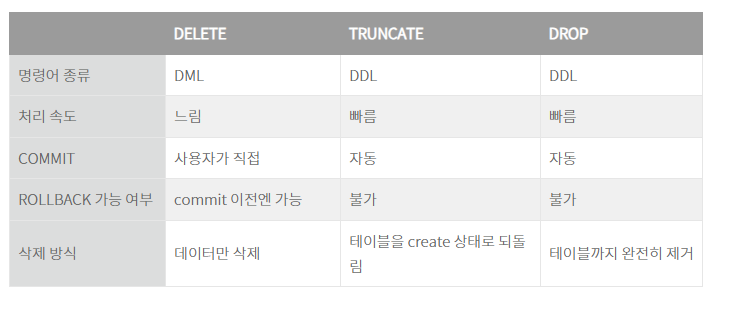
DROP과 TRUNCATE는 사용한 스토리지를 Realease하지만 delete는 아님.
DML
SELECT [컬럼명] FROM [테이블] WHERE [조건] UPDATE [테이블명] SET [컬럼 = 변경값] WHERE [조건] INSERT INTO [테이블명] (컬럼1, 컬럼2, 컬럼3) VALUES (값1, 값2, 값3) DELETE FROM [테이블명] WHERE [조건]컬럼이 4개인데 3개 INSERT = 가능
단 나머지 하나엔 Null이 들어감 = 해당 컬럼이 not null이면 에러
컬럼 지정 없이 INSERT 한다면 무조건 4개 다 넣어야 함
DEFAULT 있어도 무조건 전부!
* delete랑 from 사이에 뭐 절대로 없음
* delete [테이블] 가능
* merge: input의 키 값이 이미 존재하면 update, 없으면 insert
* 오라클은 DDL 이후 자동 커밋, SQL은 X
DML
- alter table A add column COL varchar(10)
- alter table A add ( COL1 varchar(10), COL2 varchar(10) )
- alter table A drop column COL
- atler table A modify (COL varchar(10))
- alter table A add/drop CONSAINT ~ *제약조건
DCL
- with grant option: 해당 권한을 부여할 수 있는 권한
- cascade: grant option으로 추가 부여된 권환도 회수
순수 관계 연산자
- SELECT, PROJECT, JOIN, DIVIDE
외래키 참조 동작
1) Delege or Modify
- No action
- Set Null / Dafault
- Cascade : Master 삭제시 Child 같이 삭제
- Restrict : Child에 없을때만 삭제 허용
2) Insert
- No action
- Set Null / Dafault
- Automatic : Master에 PK가 없으면 Master에 PK 자동 생성 후 Child에 입력
- Dependent : Master에 PK가 존재하면 Child에 입력 허용
*Set Null과 not Null이 겹치면 실행되지 않음
트랜잭션 특성
- 원자성
- 고립성 (서로 영향 x)
- 일관성 (실행 전에 잘못이 없다면 실행 후에도 잘못이 없음)
- 지속성 (영구히 저장)
트랜잭션 문제점
- Dirty Read : 커밋되기 전 정보를 읽음
- Non Repeatable Read : 1 트랜잭션 내 여러번의 쿼리 사이에 데이터 값이 바뀜
- Phantom Read : 1 트랜잭션 내 여러번의 쿼리 사이에 없던 값이 추가됨
서브 쿼리
- SELECT, FROM, HAING, ORDER에서 사용 가능
- select와 order by는 단일/스칼라,
- from과 having은 다중/중첩 서브쿼리
- group by에선 사용 불가
- from에선 인라인/동적 뷰를 사용
- 단일 행 연산자(부등호)는 단일 행에만 사용 가능,
- 복수 행 연산자(IN, ALL)은 단일 행, 복수 행 상관없이 사용 가능
- 메인 쿼리의 결과가 서브 쿼리로 제공될 수 있고, 반대도 가능하다
- 서브쿼리 내부에서 order by 사용 불가
- 상호 연관 (correlated) 서브 쿼리는 서브 쿼리가 메인 쿼리 컬럼을 포함하고 있는 형태 (성능 안좋음)
ex) SELECT a.name FROM a WHERE a.no = (select 1 from b where a.no = b.no)
- 비 연관 서브 쿼리는 메인 쿼리에 값을 제공하기 위해 사용된다 (연관 아님!)
뷰
- 독립성 : 테이블 구조가 변경되도 뷰를 사용하는 응용 프로그램은 변경 x
- 편리성, 보안성
- 뷰는 물리적으로 존재 x
PL/SQL
- 커서 define -> open -> fetch -> close -> exit
(커서 = 오라클 서버에서 할당한 전용 메모리 영역에 대한 포인터)
*변수와 상수 등을 사용하여 일반 SQL 문장을 실행할 때 WHERE 절의 조건 등으로 대입할 수 있다
* 프로시저 내부 절차적 코드는 PL/SQL 엔진이, 일반적인 SQL 문장은 SQL 실행기가 처리한다
* DECLARE, BEGIN~ END의 구조는 필수 // EXCEPTION은 필수 아님
=========================================================================
* 유니크 키 = 중복 불가, Null 가능
* 괄호 > NOT > 비교 연산자 > AND > OR
* 비교 연산자 = 부등호, Between, In, Like, IS NULL
* <> != ^=
* 비절차적 DML = What // 절차적 DML = How
* 오라클은 insert('')을 null로 인식한다. sql은 공백인듯?
*오라클 1 = 하루 1/24 = 1시간 1/24/60 = 1분 1/24/(60/10) = 1시간을 6등분 = 10분
* to_date(char, 서식)
* to_char(sysdate, 서식)
*권한을 한꺼번에 부여 = ROLE
* 'abc' == 'abc '
varchar면 서로 다른 값으로, char면 같은 값으로 취급
* varchar = 가변 길이 문자형, char = 고정 길이 문자형
* SELECT * FROM a WHERE name LIKE '%@_%' ESCAPE '@'
-> _가 모든 글자를 나타내는게 아닌 '_' 그 자체를 나타냄
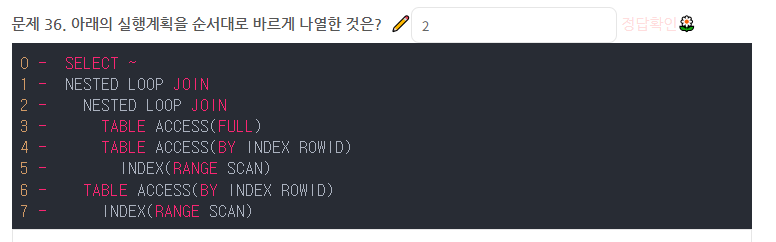
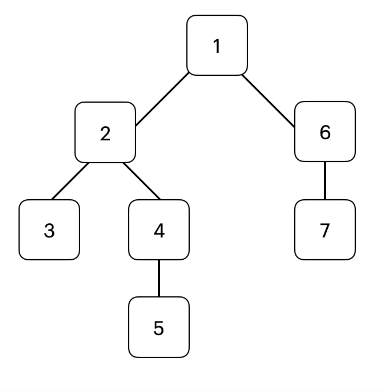
( 3 -> (54) -> 2) -> (7 -> 6) -> 1 -> 0