-
[논문]히트율에 따른 LevelDB 블룸 필터 최적화LevelDB & 블룸 필터 2023. 1. 1. 20:26

LevelDB 스터디에서 나는 블룸 필터 파트를 맡게 되었고,
단순한 수치 조정으로는 유의미한 성능 개선을 얻지 못하였었다.
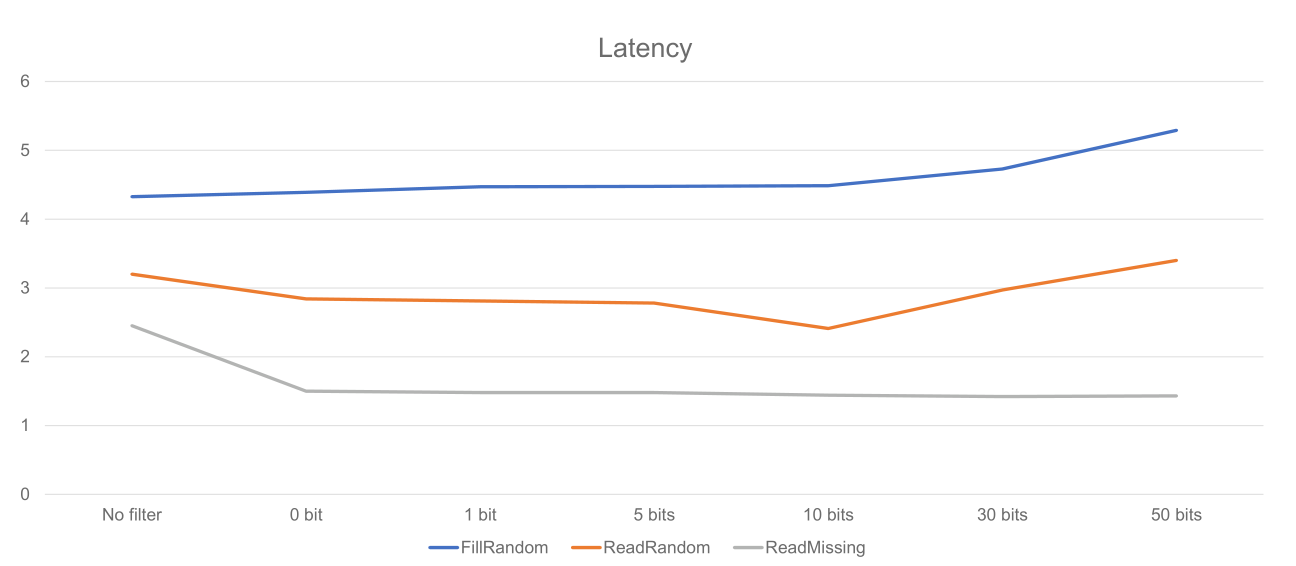
그리고 ReadMissing이라는, 데이터베이스에 존재하지 않는 key만을 탐색하는 연산의 성능을 측정하면서
독특한 점을 발견하였는데,

readmissing 연산의 경우 블룸 필터를 사용하는 것 만으로도 매우 큰 성능 개선이 발생했다.
(0bit를 사용할 경우 최소 크기의 블룸 필터가 사용된다)
나는 블룸 필터가 특정 키의 "존재" 여부를 판단한다는 점에만 집중하고 있었고,
반대로 특정 키가 "존재하지 않음"도 빠르게 알 수 있단 점을 까먹고 있었다.
그리고 두번째 특이한 점은,
bits 수를 무식하게 늘리면 성능 저하가 발생하는 read, write와 달리 readmissing에선 이가 발생하지 않았다.
이는 false positive가 "존재하지 않는" 데이터를 존재한다 판단하는 오류이므로,
존재하지 않는 데이터를 많이 탐색하느, 즉 히트율이 낮은 데이터베이스일 경우 false positive가 많이 발생하고
이는 false positive를 줄였을때 얻는 이득도 커지다는 것을 의미했다.

즉 블룸 필터의 overhead는 bits-per-key에만 비례하고,
false-positive-rate는 bits-per-key와 hit-ratio 둘 다에 영향을 받는다.
그렇다면 데이터베이스의 hit-ratio가 달라진다면, 최적의 bits-per-key 값도 변화한다는 뜻이다.

기존의 실험에서는 60% hit-ratio 환경에서만 측정을 진행하였기에,
코드를 수정하여 각각 60%, 40%, 20% 가량의 hit-ratio에 대한 read 연산을 수행하도록 하였다.

측정 결과 가설대로 데이터베이스의 hit-ratio가 감소할수록, 최적의 bits-per-key 값은 증가함을 알 수 있다.
이는 20% hit-ratio의 경우 60% hit-ratio에 비해 false-positive가 많이 발생하고,
그렇기에 bit-per-key 값을 10bits에서 15bits로 늘렸을 때 얻는
false-positive 면에서의 이득이 블룸 필터의 overhead 증가보다 컸기 때문이다.


그리고 해당 내용을 바탕으로 논문을 작성하고 ksc 2022 학회에 제출하였다.
https://www.kiise.or.kr/conference/KSC/2022/
한국정보과학회 - 학술대회 홈페이지
www.kiise.or.kr
'LevelDB & 블룸 필터' 카테고리의 다른 글
[Kakao Tech] Radix Tree + 블룸 필터 (0) 2023.01.01 LevelDB 스터디 발표 내용 정리 (0) 2023.01.01 블룸 필터 (0) 2023.01.01 LevelDB - LSM Tree (0) 2023.01.01