-
LevelDB - LSM TreeLevelDB & 블룸 필터 2023. 1. 1. 07:21

LevelDB는 구글에서 제공하는 오픈소스 키-밸류 데이터베이스이다.
1)Embedded database
기존의 데이터베이스는 어플레이케이션과 별도로 구축되어 네트워크로 통신
-> 디스크보다 훨씬 빠른 SSD를 사용하기 시작하면서 네트워크로 이를 처리하기에 역부족
-> 어플리케이션에 데이버테이스를 내장(embedded)하여 라이브러리의 형태로 사용
2)LSM-tree
Log Structured + Merge + Tree
1.Log Structured

데이터를 update할때 다른 자리에 작성
-> 수정 내역을 log처럼 모아 한번에 처리 가능 (large sequential write)
-> write 속도 대폭 증가 = 쓰기에 최적화된 자료 구조
*다만 데이터가 순서대로 저장되지 않으므로 주기적인 정렬이 필요하다.
2.Merge + Tree

메모리(C0)가 꽉 차면 데이터를 merge sort한 다음 C1으로 옮기고 이를 반복한다.
이때 스토리지는 여러 계층으로 구성되며 하위 계층일수록 더 커지는 tree의 형태를 띄게 된다.
이러한 LSM 트리의 연산은 LevelDB에서 log structure는 'Flush',
merge tree는 'Compaction'이란 연산으로 구현되어있다.


Flush:메인 메모리(c0)의 데이터를 스토리지(c1)으로 내린다
이후 데이터를 찾을땐 상위 계층의 데이터의 값을 우선적으로 리턴한다.

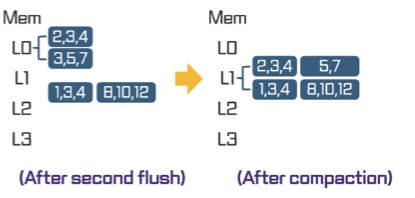
Compaction
L0이 꽉 참 -> L0의 sstable중 하나를 선택 (FIFO, LeaSt overlapped)
-> L0의 첫번째 sstable의 key range는 4부터 10이므로 이와 중첩되는 L1의 두 테이블과 merge sort
-> 중복되는 값은 제거하고 정렬하여 L1에 저장

leveled compaction (좌측) // tiered compaction (우측) 이러한 compaction은 부하가 큰 연산이기에 하나의 계층을 2개의 층으로 나눠 compaction을 수행하기도 하며
이 경우 쓰기 증폭은 감소하나 대신 공간 증폭이 늘어난다.
그리고 이러한 LevelDB에선 효과적인 데이터 탐색을 위해 추가적으로 2가지 자료구조를 사용한다


1)skiplist
정렬된 여러 층의 linked list = 빠른 검색이 가능
look up과 scan 둘 다에 유리, 특히 병렬 처리가 가능하므로 멀티 스레드 환경에 효과적
memtable은 skiplist를 활용하여 관리된다.

2)블룸 필터
sstable에 특정 데이터가 존재하는지 아닌지 빠르게 확인가능한 자료구조
자세한건

이 외에 LevelDB는 안정성을 위해 WAL(journal), 원자성을 위해 writebatch와 transaction,
무결성을 위해 checksum 기능을 제공하여 데이터베이스의 신뢰성을 보장한다.
*checksum

payload의 hast값 32bits = CRC를 저장해 이후 payload가 변경되었는지 확인


LevelDB의 전체 구조
1:WAL
2:Memtable
3:Immutable memtable
4:Flush
5:Compaction
'LevelDB & 블룸 필터' 카테고리의 다른 글
[Kakao Tech] Radix Tree + 블룸 필터 (0) 2023.01.01 [논문]히트율에 따른 LevelDB 블룸 필터 최적화 (0) 2023.01.01 LevelDB 스터디 발표 내용 정리 (0) 2023.01.01 블룸 필터 (0) 2023.01.01