-
Clustered & Non-Clustered IndexCS/자료구조 2023. 1. 5. 08:48
Index

테이블 특정 데이터로 바로 접근할 수 있게 한 자료구조
주로 해시 테이블이나 B-tree, B+ tree로 구현된다
1)해시테이블
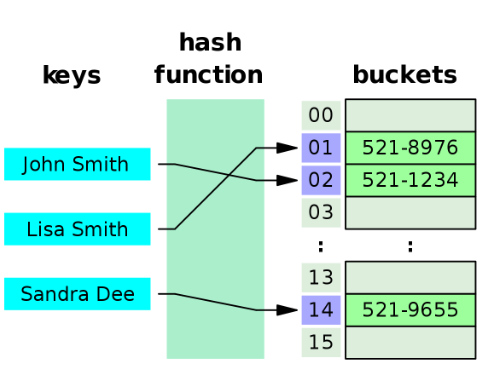
찾으려는 데이터를 input으로 얻은 해시값 = 데이터가 저장된 물리적 주소
별도의 저장 공간이 필요하지 않고, 등호 연산의 경우 시간 복잡도 O(1)로 매우 빠르다.
하지만 데이터가 정렬되어있지 않아 부등호 연산엔 효과가 없어서 DBMS에선 잘 쓰지 않는다.
2)B-tree

트리인 만큼 O(logN)으로 괜찮은 시간 복잡도를 지니고 있고
해당 노드보다 작은 key 값은 왼쪽에, 큰 값은 오른쪽에만 존재해 range search에 유리하다.
*MySQL은 index로 B-tree를 사용한다.
3)B+ tree

b+tree는 b-tree의 개선 버전으로,
모든 데이터가 leaf 노드에 연결리스트로 저장되어 있어
range scan 뿐 만 아니라 full scan에도 유리하다.
상위 노드는 data 없이 key와 pointer만 존재하므로
상위 노드에 더 많은 key를 = 트리의 높이가 낮아 fanout이 높음
이와 같이 index는 데이터베이스의 검색 속도를 향상시키지만
추가적인 index 처리 작업을 필요로 하므로
데이터베이스의 insert, update, delete가 적고
where, join, order by가 많을수록 유리하다
https://khs20010327.tistory.com/115
B-tree와 B+tree (+ ISAM tree, Bulk Loading)
1)B-tree B-tree 규칙 1)노드의 key가 k개면 자식 노드의 수는 k+1개 이다 2)모든 leaf 노드는 같은 level에 존재해야 한다 3)어느 노드는 왼쪽엔 자신보다 작은 값만, 오른쪽엔 자신보다 큰 값만을 지닌다 4
khs20010327.tistory.com
b-tree와 b+tree 자체에 대해선 따로정리
Clustered index & Non-Clustered index
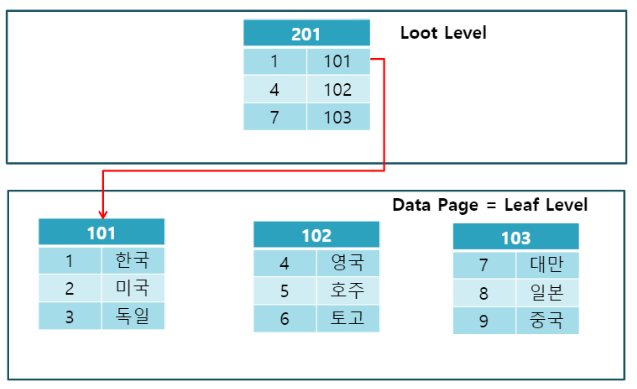
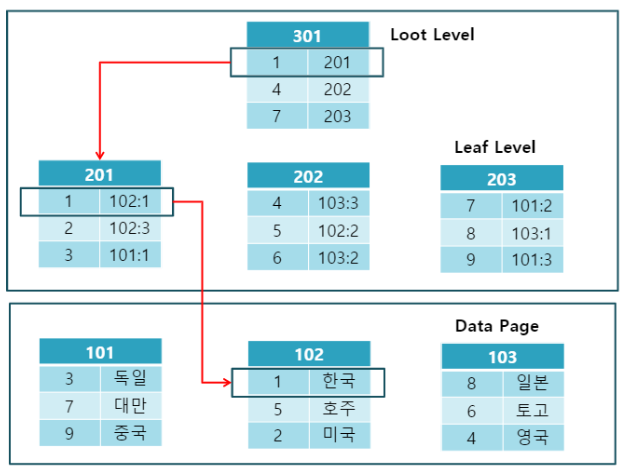
Clustered index & Non-Clustered index 쉽게 말해 clustered index는 물리적으로 정렬된 index,
non-clustered index는 논리적으로 정렬된 index이다.

Clustered index는 data entry와 data record가 동일하다.
논리적으로도, 물리적으로도 정렬되어 있어 range search나 full table scan이 매우 빠르지만
데이터를 물리적으로 정렬해야하므로 데이터의 업데이트가 잦다면 성능이 떨어진다.
한 column에 대해서만 "물리적"으로 정렬될 수 있으므로 clustered index는 한 테이블에 하나만 존재 가능하다.
항상 그렇진 않지만 primary key = clustered index로 생각하면 쉽다.
[DB] 11. 인덱스(Index) - (1) 개념, 장단점, B+Tree 등
[목차] 1. 인덱스(Index)란? 2. 인덱스(Index)의 장단점 3. 인덱스를 사용하면 좋은 경우 4. 인덱스의 자료 구조 1. 인덱스(Index)란? 인덱스(Index)는 데이터베이스의 테이블에 대한 검색 속도를 향상시켜
rebro.kr
인덱스에 대한 전체적인 개념과 장단점이 잘 적혀있음
https://helloinyong.tistory.com/296
데이터베이스 인덱스는 왜 'B-Tree'를 선택하였는가
데이터베이스의 탐색 성능을 좌우하는 인덱스. 인덱스는 데이터 저장, 수정, 삭제에 대한 성능을 희생시켜 탐색에 대한 성능을 대폭 상승하는 방식이라 볼 수 있다. DB의 인덱스는 B-tree 자료구조
helloinyong.tistory.com
해시 테이블과 b-tree 뿐만 아니라,
RedBlack-Tree, 배열, 연결리스트에 관해서도 상세히 설명되어있다.
https://stackoverflow.com/questions/37731060/range-queries-using-b-trees-and-b-trees
Range queries using B trees and B+-trees
I am writing a program to retrieve the number of objects within a given range and I am using the B-tree data structure to implement my solution as the number of objects cannot fit in RAM. I came ac...
stackoverflow.com
스택 오버플로우 하나쯤 넣어야 간지날것같아서 추가
https://gwang920.github.io/database/clusterednonclustered/
Clustered vs NonClustered (index 개념)
이번 포스팅에서는 Database의 index 와 관련된 Clustered와 NonClustered의 개념을 알아보자.
gwang920.github.io
clustered index에 대한 설명
'CS > 자료구조' 카테고리의 다른 글
해시 테이블 (0) 2023.01.13 이진 트리 & 레드 블랙 트리 (0) 2023.01.13 B-tree와 B+tree (+ ISAM tree, Bulk Loading) (0) 2023.01.07